Introduction
It is a fact universally ackowledged that the Raspberry PI is a thing of beauty. I recently stumbled across some performance test data I collected earlier this year concerning the network performance of the little things, in particular when using the (Oracle) Java Virtual Machine (JVM) versus native.
Context
At the time we were building a distributed NoSQL database built on the JVM and the Rasbian folks had recently added the Oracle JVM to the Raspian repositories. To demonstrate how a cluster of machines running the database would fare, we needed a cluster. We used AWS to build a cluster in their Ireland availability zone but I thought it would be much more fun to demonstrate a physical cluster and designed a 64-node Raspberry PI cluster demo that we could show off with and would be reasonably portable. I was convincing enough to secure a few Raspberry PIs to test but the company didn't survive long enough to publish anything about either the database or build the cluster.
In theory, the network card on a Raspberry PI model B should be able to deliver a bandwidth of about about 100 Mbits per second. This would certainly handle many database transactions per second (or a bunch of web traffic or make for a decent media server), but sometimes there is a semantic gap between what is advertised and the reality. I'd also heard various horror stories regarding former JVM network-stack implementations. The question I wanted to know was how good the Oracle JVM would be at performing network I/O operations on a Raspberry PI.
Setup
Specifically I wanted to benchmark the network I/O performance between two Raspberry PI units and also between one Raspberry PI and a conventional server over TCP.
Our inventory for the test is as follows:
- Two Raspberry PI model B units;
- A beefy server with a 1 Gbps network card;
- A switch capable of delivering 1 Gbps uncontended between two endpoints.
To measure the native network bandwidth (as seen by an application), I used a free-and-open-source benchmarking tool called iPerf:
For the JVM I used a simple Java I/O test-harness (available on my Github) that I had previously built to profile the network and disk performance of various cloud providers (Amazon, Rackspace etc.).
Results
The transfer rate over a few minutes for each of the four scenarios is shown in the plot.
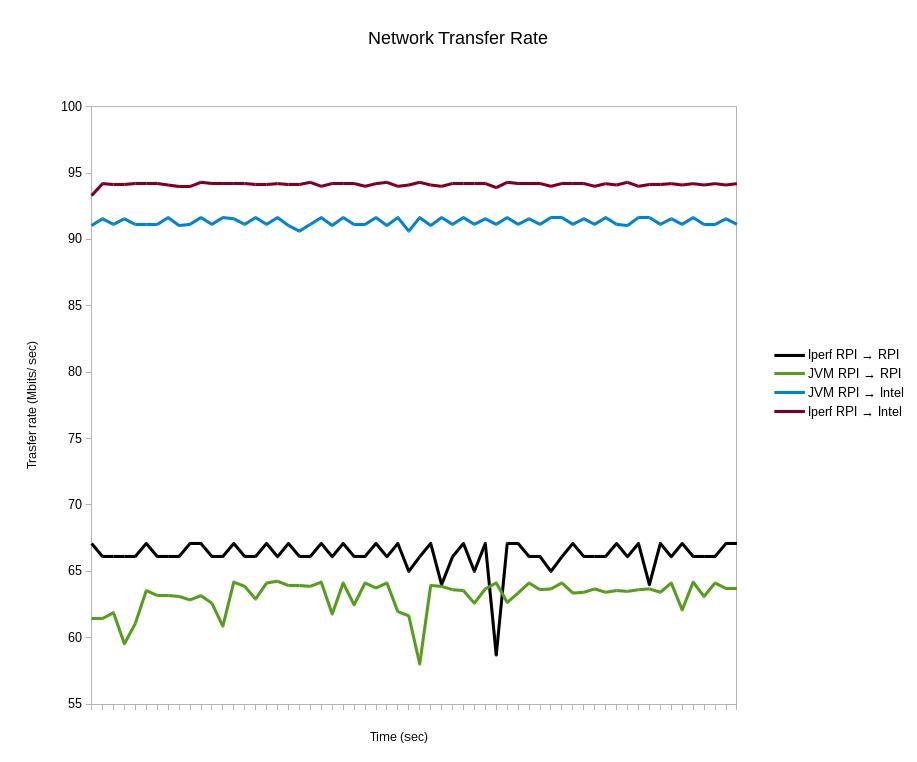
The key features I see reading this plot are:
-
From RPI to the server the transfer rate is stable using both the iPerf and my JVM code and pretty close to the advertised maximum of 100 Mbps.
-
There is a small but non-neglibible overhead using the JVM, compared to native. This was expected but it's also of the order 1% which is pretty good, props to Oracle. I didn't try too hard to optimise the JVM tests but if you see something that can be improved let me know.
-
The transfer rate is less stable when the RPI is receiving the traffic, particularly on the JVM.
-
The RPI can received a good deal less than the Network card is specced for. I tried fiddling various buffer sizes to improve the iPerf results but they seemed fairly stable at 64KB and similarly with my JVM code.
Conclusion
None of these results are too surprising but I was satisfied that they would do the job.
Go Top